SQL 성능에 큰 영향을 미치는 병목 진단하기
지난 포스트에서 오라클의 구조에 대해서 알아보았다.
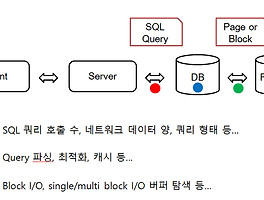
이제 SQL 쿼리를 처리하는 과정을 알아보고 어느 부분이 관심을 갖고 파헤쳐봐야 하는 부분인지 가볍게 짚어보려고 한다.
크게 나눠서 어느 부분이 대용량 SQL 처리에서 성능에 영향을 끼치는지를 확인하고 하나하나 개선하는 방법을 살펴보려고 한다. 다른 포스트에서. (지금은 큰 맥락만 이해)
SQL 처리 과정과 성능 Point
1. SQL 쿼리 입력!
2. SQL Parser가 SQL 문장에 문법적 오류가 없는지 확인 -> 문법적 오류가 없으면 의미상 오류가 없는지 확인
- 의미상의 오류는 없는 컬럼을 쓴다든지, 권한이 없는 객체를 사용했다든지 하는 오류
3. SQL 문장을 해시 함수로부터 변환한 후, 해시 값으로 라이브러리 캐시 내 해시버킷을 찾아간다.
- 라이브러리 캐시는 SQL의 실행 계획이 캐싱되는 영역이다. (실행 계획 캐시 메모리)
4. 해시 버킷에 체인으로 연결된 엔트리를 차례로 스캔하면서 같은 SQL문장을 찾는다.
5. SQL문장을 찾으면 함께 저장되어 있는 실행 계획을 가지고 바로 실행한다.
6. SQL문장을 찾지 못하면 "최적화"를 수행한다.
7. 최적화를 거친 SQL과 실행 계획을 방금 탐색한 해시 버킷 체인에 연결한다.
8. 방금 최적화한 실행 계획을 가지고 실행한다.
SQL 쿼리를 입력했을 때 데이터베이스에서 처리하는 과정을 위와 같다. (이해를 돕기위한 핵심은 아래에서 설명한다.)
SQL을 실행할 때 SQL을 바로 실행하는 것이 아니라 가장 최소한의 시간이 걸리도록 즉, 성능이 가장 좋은 방법(=실행 계획)이 무엇인지 찾는다.
그렇게 해서 가장 최적화된 실행 계획을 찾으면 라이브러리 캐시에 넣는다.
그것을 다음에도 똑같은 SQL문이 왔을 때 캐시에 있으면 해당 SQL의 최적화된 실행계획은 이미 있으니 바로 실행해버리면 되는 것이다.
결과적으로 성능 향상의 포인트는 이 최적화 과정을 거치느냐 거치지 않느냐다.
참고로 최적화는 단순하게 예를들어 테이블 5개(A,B,C,D,E)를 조인한다치면 5!=120개의 조인 순서를 정하는 방법이 있고 인덱스는 어떻게 할지 어떤 조인을 사용했는지 까지고려하면 엄청나게 성능에 악영향을 끼치는 부분이다.
- 소프트 파싱 : SQL과 실행계획을 캐시에서 찾아서 바로 실행하는 경우(최적화X)
- 하드 파싱 : SQL과 실행계획을 캐시에서 찾지 못해서 최적화 과정을 거친 후 실행하는 경우(최적화O)
실행 계획을 공유하지 못하는 경우와 개선 방향
결국은 대부분의 SQL이 실행 계획을 공유하는 것이 곧 최적화 과정을 최소화하는 방법이고 성능 향상에 큰 도움이 된다는 것이다.
그럼 이제 실행 계획을 공유하지 못하는 경우를 살펴본다.
1. 공백 문자 혹은 줄바꿈
1 2 | SELECT * FROM JEONGPRO SELECT * FROM JEONGPRO |
2. 대소문자 구분
1 2 | SELECT * FROM JEONGPRO SELECT * FROM jeongpro |
3. 주석
1 2 | SELECT * FROM JEONGPRO SELECT /*주석처리*/ * FROM JEONGPRO |
4. 테이블 Owner 표시
1 2 | SELECT * FROM JEONGPRO SELECT * FROM JDK.JEONGPRO |
5. 옵티마이저 힌트 사용
1 2 | SELECT * FROM JEONGPRO SELECT /*+all_rows*/ * FROM JEONGPRO |
6. 조건절 비교 값 변화
1 2 3 4 | SELECT * FROM JEONGPRO WHERE LOGIN_ID = 'jeong' SELECT * FROM JEONGPRO WHERE LOGIN_ID = 'pro' SELECT * FROM JEONGPRO WHERE LOGIN_ID = 'jdk' SELECT * FROM JEONGPRO WHERE LOGIN_ID = 'oracle' |
=> 공백 문자만으로도 다른 SQL로 인식해서 실행계획이 달라지는 것을 알 수 있다. 위와 같이 SQL문을 작성하지 않도록 주의하자.
그런데 이런 얘기를 하고자 한게 아니라 유심히 봐야할 것은 6번이다. 6번은 사실 억울하다. 조건절의 리터럴만 달랐을 뿐인데 다 다르게 판단하고 다 다른 실행계획을 갖는다면 엄청난 성능 장애를 겪을 수 있다.
위의 예제처럼 실행계획이 다 다른 상황에서 수백만명이 로그인을 한다고 하면 시스템 장애가 온다.
이런 방법을 개선해보자.
바인드 변수를 사용하자
1 | SELECT * FROM JEONGPRO WHERE LOGIN_ID = :LOGIN_ID; |
이렇게 바인드 변수를 사용하고 아까 6번과 같은 쿼리가 100만번 수행한다면, 최초 1회 때 최적화 과정을 거친 후 캐시되고 나머지는 실행 계획을 공유해서 금방 실행될 것이다.
바인드 변수를 쓰지 않아도 되는 상황은 아래와 같다.
- 수행빈도가 아주 낮을 때 (어쩌다 가끔 실행되는 쿼리)
- 조건절 컬럼의 값 종류가 적을 때 (ex. 남/여, 1~12월등..)
사실 바인드 변수를 따로 사용하지 않아도 조건절에 리터럴 상수가 왔을 때 바인드 변수화 시켜주는 기능이 있다.
mssql은 auto-parameterization이 저절로 활성화되고 oracle은 cursor_sharing 파라미터를 FORCE or SIMILAR로 설정하면 된다.
대신 부작용도 엄청나다. 이 옵션을 적용하는 순간에 실행계획이 바뀌면서 부하가 엄청 걸릴 수 있고 사용자가 의도적으로 사용한 상수까지 전부다 변수화시키면서 문제를 일으킬 수도 있다.
이런 부작용을 없애기위해 Oracle9i부터는 바인드 변수 peeking 기능도 생겼는데 이 기능은 SQL이 첫 번째 수행될 때 바인드 변수 값을 살짝 훔쳐 보고, 그 값에 대한 컬럼 분포를 이용해 실행계획을 결정하는 기능이다.
역시나 위험한 기능인게 처음 입력된 값과 전혀 다른 분포의 값이 입력되는 순간 쿼리 성능이 확 떨어지는 현상이 나온다.
결국 oracle 11g에서는 Adaptive Cursor Sharing이라는 기능이 도입되었으나 완전히 검증된 것이 아닌 기능이기에 바인드 변수를 잘 사용하는 것은 여전히 중요하다.
Static SQL과 Dynamic SQL
Static SQL은 String형 변수에 SQL을 담지 않고 직접 기술하는 SQL문으로 Embedded SQL이라고도 한다.
Dynamic SQL은 String형 변수에 SQL을 담아서 기술하는 SQL문이다. (거의 모든 프로그래밍 언어에서는 Dynamic SQL만 지원한다고 보면 된다.)
(+Syntax, semantics 체크가 불가능)
중요하지 않다.
애플리케이션 커서 캐싱
SQL 쿼리문의 처리 과정도 이해했고 중요한 부분인 바인드변수도 알았다.
그러면 다른 부분은 안봐도 될까? 그건 또 아니다.
여전히 SQL문장의 문법적, 의미적 오류를 확인하고 해시함수를 타서 실행계획을 찾고 실행에 필요한 리소스를 사용하는 등의 과정은 그대로 반복된다.
이런 과정마저 생략하고 빠르게 수행하는 방법을 "애플리케이션 커서 캐싱"이라고 한다.
Java에서는 묵시적 캐싱을 사용하면 된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | public static void CursorCaching(Connection conn, int count) throws Exception{ //캐시 사이즈 1 ((OracleConnection)conn).setStatementCacheSize(1); //묵시적 캐싱 기능 활성화 ((OracleConnection)conn).setImplicitCachingEnabled(true); for(int i=1;i<=count;i++){ PreparedStatement stmt = conn.prepareStatement( "SELECT ?,?,?,a.* FROM emp a WHERE a.ename LIKE 'W%'"); stmt.setInt(1,i); stmt.setInt(2,i); stmt.setString(3,"test"); ResultSet rs = stmt.executeQuery(); rs.close(); stmt.close(); } } |
또는 statement를 닫지 않고 사용하는 것도 가능하다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | public static void CursorCaching(Connection conn, int count) throws Exception{ PrepareStatement stmt = conn.prepareStatement( "SELECT ?,?,?,a.* FROM emp a WHERE a.ename LIKE 'W%'"); ResultSet rs; for(int i=1;i<=count;i++){ stmt.setInt(1,i); stmt.setInt(2,i); stmt.setString(3,"test"); ResultSet rs = stmt.executeQuery(); rs.close(); } //루프가 다 끝난 후 따로 커서를 닫음 stmt.close(); } |
이렇게 해서 SQL문이 날라왔을 때 데이터베이스에서 처리되는 과정을 이해했다.
또한 성능에 문제를 끼치는 부분을 캐시, 최적화과정을 통해 알 수 있었고
그 외에 불필요한 과정을 생략하는 방법도 알았다.
이번 포스트를 통해서 SQL 쿼리 성능 최적화를 시킨다는 개념보다는 이런 부분을 주의깊게 봐야하는구나를 파악하면 되고, 다음의 다른 포스트에서 본격적으로 성능 최적화를 다뤄볼 것이므로 그때 또 공부해본다.