MySQL LIMIT 최적화(feat. 구글이 검색결과를 최대 1,000건만 제공하는 이유)
제가 말하는 것이 사실도, 정답도 아닐 수 있으니 비판적으로 읽어주시면 감사하겠습니다.
MySQL LIMIT 최적화하는 방법
MySQL에서 페이징 처리를 위하여 LIMIT 키워드를 제공한다.
오라클에서는 페이징 처리를 위해 rownum 으로 레코드에 번호를 부여하고 WHERE 절에 조건 걸어서 일일이 페이징 처리하던 것에 비해 훨씬 편리하여 자주 사용된다.
이러한 페이징 처리 방법을 오프셋(offset) 페이징이라 한다.
MySQL에서 제공하는 LIMIT 즉, 오프셋 페이징에는 치명적인 단점이 있다.
그것은 바로 오프셋 만큼 레코드를 읽어온 후에 필요한 레코드 수를 제외한 "나머지는 버리는 방식"으로 동작하는 것이다.
예를 들어 쿼리가 SELECT ... LIMIT 5000000, 10 처럼 LIMIT 오프셋의 값이 500만(큰 수)일 때, 500만 번 째까지 레코드를 전부 읽고 그 이후로 10개까지 레코드를 읽은 후, 앞에 필요 없는 500만 개의 레코드를 버리는 식으로 동작한다.
이것이 뭐가 위험하냐면 "레코드를 읽는다"라 함은 커버링 인덱스를 적용한 것이 아니라면 디스크 I/O가 발생한다고 볼 수 있다.
위의 예시에서는 500만이었지만 훨씬 더 큰 5,000만 건, 1억 건을 읽을 수도 있는 것이다.
따라서 LIMIT은 최적화해야 하는 대상이다. 어떻게 해야 할까?
LIMIT 최적화에 앞서 알아야 할 것
사실 대규모 서비스를 제공하는 회사를 다녀서 대용량 처리를 해야 하는 경우가 아니라면, LIMIT를 그냥 사용해도 무방하다.
그 이유는 애플리케이션에서 페이징을 사용하는 사람들의 이용 패턴에 있다.
사람들은 대부분의 경우에 10페이지 이상 넘어가서 보려고 하지 않는 성질(?) 특징(?)이 있다.
다시 말해서 100페이지 또는 5,000페이지에 있는 결과를 보려고 하지 않기 때문에 대부분의 경우에 많은 레코드를 읽지 않아 성능 문제를 일으키지 않는다.
그러나 모든 사용자가 낮은 숫자의 페이지만 요청하고 뒤 높은 숫자의 페이지는 요청하지 않을 것이라고 단정해서는 안된다.
뿐만 아니라 누군가 악의적으로 5,000,000 페이지에 있는 데이터를 여러 번 요청하여 DB 커넥션 및 트랜잭션을 오래 점유(성능 문제)하여 다른 사용자에게 서비스하지 못하게 할 수도 있다.
최적화 방법
이를 최적화하는 방법은 두 가지다.
인덱스를 이용하는 방법
앞서 어디가 문제의 포인트인지 알 수 있었다.
바로 500만 건을 읽고 버리는 게 문젠데 이를 해결하기 위해서 500만 번째 레코드로 한 번에 갈 수 있으면 해결이 된다.
(엄밀하게 한 번에는 아니지만) 한 번에 가는 그 방법으로 인덱스를 이용하는 것이다.
SELECT * FROM salaries ORDER BY id LIMIT 0, 10; -- (1)
SELECT * FROM salaries ORDER BY salary LIMIT 0, 10; -- (2)
-- salary와 id 각각 인덱스가 생성되었다고 가정한다.위의 쿼리는 1 페이지에 해당하는 쿼리로 테이블 풀 스캔을 하지만 10개를 찾자마자 결과 레코드 10개를 읽어서 리턴하므로 성능에 문제가 없고 쿼리도 개선 전과 동일하다.
그다음은 2 페이지를 가져오는 쿼리다.
SELECT * FROM salaries
WHERE id > 15
ORDER BY id LIMIT 0, 10; -- (1)
SELECT * FROM salaries
WHERE salary >= 35647 AND (salary=35647 AND id <= 15)
ORDER BY salary LIMIT 0, 10; -- (2)해법으로 WHERE 절에 인덱스 컬럼에 조건을 줘서 인덱스 위치를 탐색 후 순차적으로 필요한 10개만큼 스캔하는 것이다.
앞서 1페이지를 조회했을 때 얻은 10번째 레코드의 값(예를 들어 id=15, salary=35647이라고 가정)으로 다음 페이지를 조회할 때 활용하는 것이다.
2개의 경우를 보여준 것은 이유가 있다.
(1)의 경우, id 컬럼은 primary key로 중복도 없고 autoincrement로 순차적으로 생성되기 때문에 단순하게 처리했다.
그러나 (2)의 경우, salary 값이 인덱스 컬럼일지라도 중복이 될 수 있기 때문에 뒤에 AND (salary=35647 AND id≤15)로 중복이나 누락을 없애주는 조건도 들어갔다.
마찬가지로 2 페이지를 조회했을 때 얻은 20번째 레코드의 값을 사용하여 아래와 같이 3 페이지의 레코드도 가져올 수 있다. (이런 식으로 N 페이지의 레코드도 성능 저하 없이 가져오겠다는 방법...)
이러한 방법을 커서 페이징이라고 하는 것 같다.(확실하지 않은 정보고 커서 역할을 하는 컬럼을 이용하여 앞 뒤로 가져오는 방법이긴 하다.)
-- 2페이지에서 가져온 20번째 레코드의 id = 26, salary = 40000
SELECT * FROM salaries
WHERE id > 26
ORDER BY id LIMIT 0, 10;
SELECT * FROM salaries
WHERE salary >= 40000 AND (salary=40000 AND id <= 26)
ORDER BY salary LIMIT 0, 10;🤔 뭔가 좀 이상하다.
1부터 500페이지를 순차적으로 가야지만 인덱스 컬럼의 값을 알고 적용할 수 있는 방안이 아닌가?!
맞다.
단 번에 500만 페이지로 넘어가는 사람도 생각을 해야 한다.
그러나 이는 두 번째 방법을 알아본 후에 더 알아보기로 한다.
커버링 인덱스를 이용한 방법
두 번째 방법은 커버링 인덱스를 이용하는 방법이다.
이 방법은 쿼리를 수정하지 않고 그대로 오프셋을 적용하지만 커버링 인덱스를 사용하도록 하는 것이다.
커버링 인덱스는 간단하게 설명하면 실제 레코드에 접근할 필요 없이 인덱스의 컬럼만으로 SELECT 쿼리의 결과를 만들 수 있을 때 이를 커버링 인덱스라 한다.
SELECT id, emp_id, emp_name, salary
FROM salaries
where from_date >= '2000-01-01'
LIMIT 5000000, 10위와 같은 쿼리라고 하면 (id, emp_id, emp_name, salary, from_date)로 구성된 인덱스가 생성되어 있어 굳이 레코드를 읽지 않아도 처리가 가능한 경우를 말한다.
이러면 뭐가 최적화냐 할 수 있는데 이렇게 되면 모든 값이 메모리에 있으므로 500만 인덱스 레코드를 스캔하는데 금방 처리할 수 있는 것을 기대하는 것이다.
구글이 최대 1,000건의 검색 결과만 제공하는 이유
아까 남겨둔 이슈가 있다.
바로 단 번에 큰 수의 페이지(500만 번째 페이지)로 넘어갈 때 최적화가 가능한가? 에 대한 이슈다.
결론부터 얘기하면 답이 없다. (적어도 필자가 아는 한. 고로 적절한 처리방법을 아는 분은 댓글로 힌트라도 남겨주시면 감사하겠다.)
구글은 어떻게 하나?
1, 2, 3, ... 이렇게 페이징을 제공하는 데가 어디 있을까 하다가 구글이 떠올랐다.
구글이 어떻게 페이징 처리를 하는지 봤는데 결과적으로 구글은 최대 1,000개의 검색 결과만 제공했다. (강제로 4,000페이지로 가봤는데 예외처리가 되었다.)
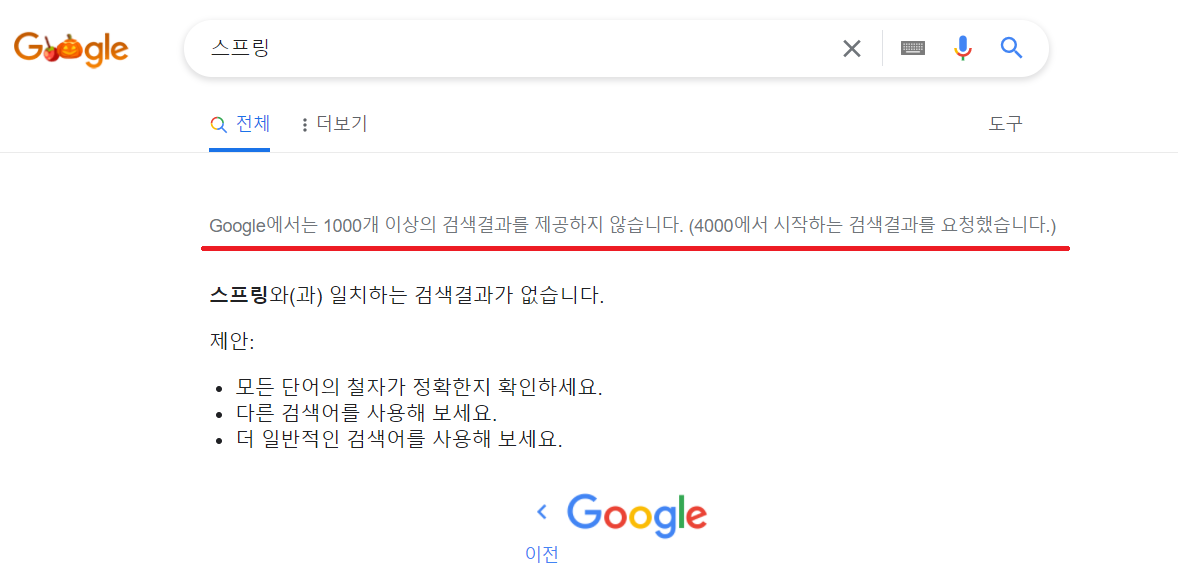
즉, 페이지가 500만 페이지는커녕 50페이지 안 쪽에서 그냥 끝나게 처리해둔 것이다.
우연히 보게 된 또 다른 특징으로 구글은 검색 결과의 수를 대략적으로 표시한다.
RDB를 쓰는지도 모르면서 하는 추측이지만, 아마도 COUNT 하는데도 이슈가 있기 때문에 실제 카운트 수가 아닌 통계 데이터에서 가져온 게 아닐까 싶다.
또 다른 특징으로는 페이지가 1~10, 11~20, 21 ~30, ... 이런 식으로 페이지 네비게이션(?)이 구성되지 않는다.
첫 페이지에서는 1~10으로 보이지만 예를 들어 10번 페이지로 가면 앞뒤로 5개씩 해서 6~14 이렇게 나온다.
(관심법 같은 추측이지만 이렇게라도 해서 뒤에 있는 페이지에 접근하는 것을 최대한 적게 유도하는 듯했다.)
구글은 페이지를 로드하는 데 걸린 시간도 알려주는데 네트워크 환경마다 다르겠지만 첫 페이지는 0.44초가 걸렸고, 45페이지에 있는 결과를 가져올 때 2초 이상 걸렸다.
인스타는 어떻게 하나?
인스타는 500페이지로 단 번에 가능 방법 자체를 제공하지 않는 것 같다.
무조건 무한 스크롤로 더 보기 하게 하여 순차적으로 가져오도록해서 이미지를 제공하는 것 같다.
보통 무한 스크롤에서 10개씩 가져온다면 뒤에 가져와야 할 대상 한 개를 10개 가져올 때 미리 가져오거나 유사하게 다음 레코드의 정보까지 가져와서 더보기 같이 다음을 보려고 할 때 그 정보를 가지고 쿼리 해온다.
네이버는 어떻게 하나?
네이버도 마찬가지로 10페이지까지 밖에 제공하지 않는다.
아래 그림처럼 "최상의 검색결과를 제공하기 위해..."라는 멘트가 있지만 실제로 기술적으로 어렵기 때문인 듯하다.

그러나 이렇게 물러설 수 없었다.
네이버가 포털사이트에서 쇼핑몰로 변화했기 때문에 바로 네이버 쇼핑은 어떻게 하나 봤다.
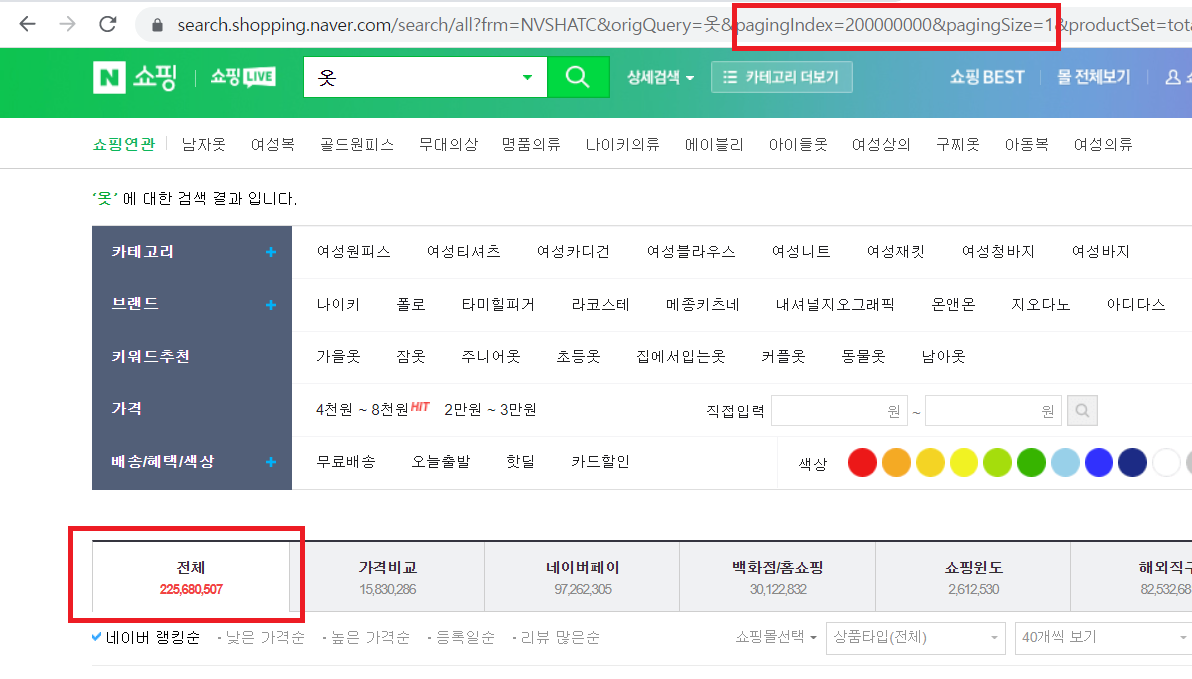
그냥 LIMIT 을 최적화 없이 쓰는 건 아닌 듯하지만 뭔가 그런 듯 애매하게 보인다.
(물론 RDB라고 단정지으면 안되기도 한다 + 댓글에 HBase로 쿼리한다고 한다.)
상품정보가 가장 많이 나올만하다고 생각한 "옷"이라는 키워드로 검색했더니 2억 건 이상 있었다. (카운트도 정확한지는 모르겠지만 구체적으로 보이게 해놨다.?!)
URL의 RequestParam? QueryString? 을 조작하여 엄청나게 뒤에 페이지로 가도록 조작해봤으나, 한 페이지에 보일 상품의 수가 최소 40개인 듯하여 자동으로 약 500만 페이지로 가졌다.
그럼에도 한 2~3초밖에 안 걸리는 듯하게 결과가 나왔다.
실제로 2억 건을 읽고 버리는데 2~3초가 나오기는 어려워 보이는데 어떻게 된 건지 자세한 건 네이버에 다니는 분이 댓글로 상세한 것을 알려주거나 네이버 다니는 지인이 알려주는 방법밖에 없어 보였다.
결론
- 대규모 서비스가 아니고 성능이 크게 중요하지 않다면 그냥 LIMIT 페이징 쓰기
- 대규모 서비스여서 최적화를 해야 한다면 두 가지 중에 하나 정책으로 정하기
- 오프셋 페이징을 하되, 최대 페이지 번호를 지정하여 성능 문제가 일어나지 않도록 하는 정책으로 정하기
- 무한 스크롤 형태 즉, 커서 페이징을 하되 한 번에 많이 뒷 페이지로 가는 페이징할 수 없는 제약이 있는 정책으로 정하기